
Google’s Tacotron 2 simplifies the process of teaching an AI to speak

Creating convincing artificial speech is a hot pursuit right now, with Google arguably in the lead. The company may have leapt ahead again with the announcement today of Tacotron 2, a new method for training a neural network to produce realistic speech from text that requires almost no grammatical expertise.
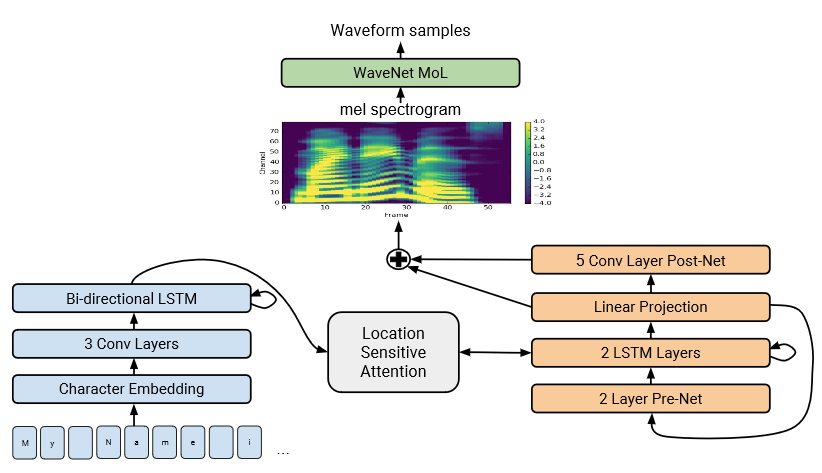
The new technique takes the best pieces of two of Google’s previous speech generation projects: WaveNet and the original Tacotron.
WaveNet produced what I called “eerily convincing” speech one audio sample at a time, which probably sounds like overkill to anyone who knows anything about sound design. But while it is effective, WaveNet requires a great deal of metadata about language to start out: pronunciation, known linguistic features, etc. Tacotron synthesized more high-level features, such as intonation and prosody, but wasn’t really suited for producing a final speech product.
Tacotron 2 uses pieces of both, though I will frankly admit that at this point we have reached the limits of my technical expertise, such as it is. But from what I can tell, it uses text and narration of that text to calculate all the linguistic rules that systems normally have to be explicitly told. The text itself is converted into a Tacotron-style “mel-scale spectrogram” for purposes of rhythm and emphasis, while the words themselves are generated using a WaveNet-style system.

That should make everything clear!
The resulting audio, several examples of which you can listen to here, is pretty much as good as or better than anything out there. The rhythm of speech is convincing, though perhaps a bit too chipper. It mainly stumbles on words with pronunciations that aren’t particularly intuitive, perhaps due to their origin outside American English, such as “decorum,” where it emphasizes the first syllable, and “Merlot,” which it hilariously pronounces just as it looks. “And in extreme cases it can even randomly generate strange noises,” the researchers write.
Lastly, there is no way to control the tone of speech — for example upbeat or concerned — although accents and other subtleties can be baked in as they could be with WaveNet.
Lowering the barrier for training a system means more and better ones can be trained, and new approaches integrated without having to re-evaluate a complex manually defined ruleset or source new such rulesets for new languages or speech styles.
The researchers have submitted it for consideration at the IEEE International Conference on Acoustics, Speech and Signal Processing; you can read the paper itself at arXiv.
Featured Image: Bryce Durbin/TechCrunch
Published at Tue, 19 Dec 2017 21:48:25 +0000



{kind=link}